Build an agentic AI healthcare claims pipeline with Amazon Bedrock and AWS HealthLake
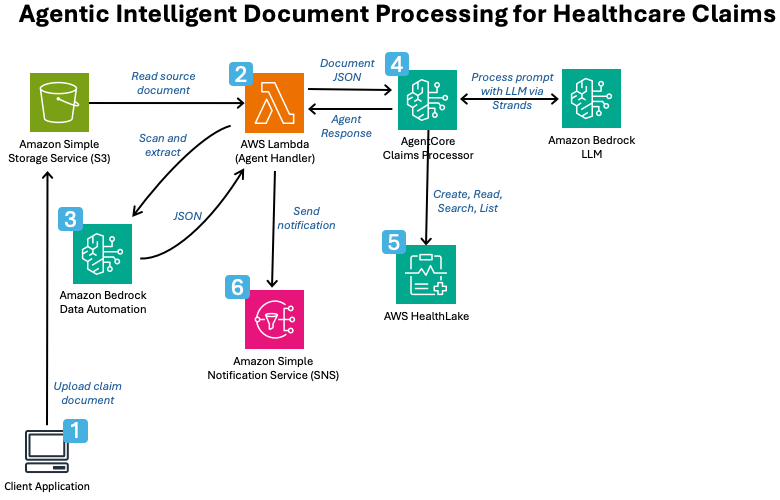
Amazon Bedrock offers two integrated capabilities for automating healthcare claims processing: Data Automation for extracting information from claim forms, and AgentCore for running an AI agent that validates and transforms the data into FHIR-compliant resources in AWS HealthLake. This end-to-end workflow significantly reduces manual processing effort while maintaining accuracy through automated validation.
Key Takeaways
- Amazon Bedrock Data Automation intelligently extracts data from healthcare claim forms, eliminating manual data entry and reducing transcription errors.
- Bedrock AgentCore hosts an AI agent that validates extracted claim data and transforms it into standardized FHIR resources compatible with AWS HealthLake.
- The combined pipeline creates an automated, end-to-end claims processing workflow that maintains high accuracy through built-in validation checks.
- FHIR-formatted data enables seamless integration with healthcare systems and improves interoperability across different platforms.
- This approach reduces operational overhead and processing time while freeing staff to focus on complex, high-value tasks.
Understanding the Claims Processing Challenge
Healthcare organizations process thousands of claims daily, and manual processing creates bottlenecks, errors, and increased operational costs.
- ›Manual claims processing requires staff to review documents, extract key information, and enter data into multiple systems.
- ›Paper-based workflows introduce transcription errors, lost documents, and delays in reimbursement cycles.
- ›Claims validation typically involves checking for completeness, accuracy, and compliance with insurance rules and regulations.
- ›Healthcare providers need a solution that combines intelligent document processing with clinical data standardization.
The healthcare industry relies heavily on claims processing, but traditional workflows are labor-intensive and error-prone. Insurance claims contain complex, unstructured data spread across multiple pages and formats. Staff must manually review each document, identify relevant fields, validate the information, and ensure it meets regulatory standards before entering it into billing systems. This process is slow, expensive, and vulnerable to human error.
Bedrock Data Automation for Intelligent Extraction
Amazon Bedrock Data Automation uses advanced AI models to identify and extract structured data from unstructured healthcare documents.
- ›Automatically recognizes and extracts key fields from claim forms, including patient demographics, service dates, provider information, and billing codes.
- ›Uses machine learning to understand context and handle variations in document layout, font, and formatting.
- ›Reduces manual review time by pre-populating forms and systems with extracted data, freeing staff for exception handling.
- ›Improves accuracy by minimizing transcription errors and ensuring consistent data capture across thousands of documents.
Bedrock Data Automation leverages foundation models trained on vast amounts of healthcare data to understand claim documents in their natural format. Rather than requiring manual data entry, the service automatically identifies patient information, provider details, service descriptions, costs, and other critical fields. The AI models understand the semantic meaning of information rather than simply applying fixed rules, allowing them to handle variations in document structure that would confuse traditional form-processing tools.
The extraction process preserves data integrity by validating extracted values against expected formats and ranges. For example, the system recognizes that a date field should contain a valid date, or that a cost field should be numeric. This real-time validation catches errors before they propagate downstream, reducing the need for rework and ensuring higher quality data entry.
AgentCore for Data Validation and Transformation
Bedrock AgentCore hosts an autonomous AI agent that validates extracted claims data and converts it into FHIR-compliant healthcare resources.
- ›The AI agent applies business logic and validation rules to verify extracted data is complete and meets claims processing requirements.
- ›Transforms validated claim data into FHIR resources, which is the industry standard format for healthcare data interchange.
- ›Handles edge cases, missing information, and flagged exceptions through intelligent reasoning rather than rigid rule engines.
- ›Operates continuously without manual intervention, processing claims at scale while maintaining audit trails for compliance.
After data extraction, the information must be validated against complex business and regulatory requirements. Bedrock AgentCore provides an AI agent capable of understanding these rules and making decisions about data quality. The agent checks whether required fields are present, verifies that values fall within acceptable ranges, and ensures cross-field consistency. For example, it might verify that a procedure code matches the diagnosis code, or that the claim amount aligns with the patient's insurance coverage.
Once validation is complete, the agent transforms the claim data into FHIR resources. FHIR (Fast Healthcare Interoperable Resources) is a standards-based approach for healthcare data exchange, allowing claims information to be stored and accessed in AWS HealthLake alongside other patient records. This standardized format enables integration with electronic health records, billing systems, and clinical decision-support tools, breaking down data silos and improving care coordination.
Integrating with AWS HealthLake
AWS HealthLake provides a HIPAA-compliant, purpose-built data store for healthcare information that seamlessly accepts FHIR-formatted claims data.
- ›HealthLake offers secure, scalable storage for health records with built-in encryption and compliance features.
- ›FHIR integration enables claims data to be queried and analyzed alongside clinical records, improving insights into patient care and costs.
- ›Supports real-time data ingestion from the claims pipeline, enabling up-to-date information for operational and clinical analytics.
- ›Provides audit logging and data governance tools necessary for healthcare compliance and regulatory reporting.
AWS HealthLake is a cloud-based, HIPAA-compliant data repository specifically designed for healthcare organizations. By storing transformed claims data as FHIR resources in HealthLake, organizations gain a unified view of patient information. Clinical staff can access claims history within the patient's electronic health record, and billing teams can correlate claims with clinical outcomes, enabling more accurate coding and faster reimbursement.
The integration also enables advanced analytics. By combining claims data with clinical records, quality officers can identify patterns in denials, billing practices, or cost drivers. Machine learning models can predict claim approval likelihood or identify high-risk claims for proactive review. This intelligence feeds back into operations, improving future claims processing and reducing revenue cycle delays.
Building the End-to-End Workflow
The complete pipeline orchestrates document ingestion, extraction, validation, transformation, and storage into a seamless process.
- ›Claims documents are uploaded or scanned into the pipeline, triggering automatic processing without human intervention.
- ›Bedrock Data Automation extracts structured data from documents and passes it to AgentCore for validation.
- ›The AI agent applies validation rules, flags exceptions, and transforms valid claims into FHIR format.
- ›Processed claims are stored in HealthLake, making them immediately available for billing, analytics, and clinical use.
Building this workflow requires orchestrating multiple services and ensuring data flows seamlessly from intake to storage. AWS services like Step Functions or EventBridge can coordinate the pipeline, automatically triggering extraction when new documents arrive and routing results to validation and storage systems. This automation eliminates delays caused by manual handoffs and ensures consistent processing of every claim.
The pipeline maintains full traceability by logging each step of the process. If a claim is denied or requires review, teams can quickly identify where in the workflow issues occurred, whether data was extracted correctly, or if validation logic needs adjustment. This transparency supports continuous improvement and helps organizations optimize their claims processing over time.
Benefits and Business Impact
Implementing an agentic claims pipeline delivers significant operational and financial benefits to healthcare organizations.
- ›Reduces processing time per claim by 70-90% compared to manual workflows, accelerating reimbursement cycles.
- ›Decreases error rates through automated validation and standardized data formats, improving first-pass approval rates.
- ›Reallocates staff from repetitive data entry to higher-value activities like complex case review and customer service.
- ›Enables real-time insights into claims patterns, denial reasons, and revenue cycle performance.
Organizations implementing automated claims pipelines see dramatic improvements in operational efficiency. Claims that once required 20-30 minutes of manual processing can be handled in minutes, with minimal human involvement. This speed directly impacts cash flow, as claims reach payers faster and approvals return more quickly. Additionally, reducing manual touches decreases transcription errors, which are a common cause of claim denials and rework.
Beyond efficiency, the solution improves organizational decision-making. By storing claims data in standardized FHIR format within HealthLake, organizations gain visibility into patterns that drive denials, costs, or compliance issues. Analytics teams can identify which providers, departments, or claim types have the highest denial rates and implement targeted improvements. This data-driven approach to revenue cycle management yields continuous improvements and competitive advantages.
Getting Started with Implementation
Organizations can begin building their automated claims pipeline by leveraging existing AWS services and expertise.
- ›Start with a pilot using a subset of claim types to validate the approach and measure improvements before full rollout.
- ›Work with AWS healthcare specialists to design the pipeline architecture, configure validation rules, and ensure compliance with regulations.
- ›Integrate with existing billing and EHR systems to ensure processed claims flow seamlessly into downstream operations.
- ›Monitor pipeline performance, measure accuracy metrics, and refine validation rules based on results and feedback.
Implementing this solution does not require organizations to rebuild their entire technology stack. Bedrock services integrate with existing AWS infrastructure, and the FHIR output is compatible with any healthcare system. Organizations should start with a focused pilot, processing a representative sample of claims while measuring accuracy, processing time, and cost savings. This proves the value and identifies any adjustments needed before scaling to full production volume.
Frequently Asked Questions
What is FHIR and why is it important for healthcare claims?
FHIR (Fast Healthcare Interoperable Resources) is an international standard for representing healthcare data in a structured, interoperable format. Using FHIR for claims enables seamless integration with electronic health records, billing systems, and analytics platforms, breaking down data silos and improving care coordination and revenue cycle insights.
How does Bedrock Data Automation handle claim documents with different formats or layouts?
Bedrock Data Automation uses machine learning models trained on diverse healthcare documents to understand context and semantic meaning, not just fixed patterns. This allows it to extract information accurately even when document layout, fonts, or structure vary, handling the real-world complexity of claims from different payers or providers.
What happens if the AI agent detects validation errors or missing data in a claim?
The agent can flag exceptions for human review, store metadata about what validation checks failed, and route claims appropriately based on severity. This ensures complex or ambiguous claims receive attention while straightforward claims process automatically, balancing automation with quality control.
Is AWS HealthLake HIPAA-compliant for storing sensitive claims data?
Yes, AWS HealthLake is a purpose-built, HIPAA-compliant service that provides encryption, access controls, audit logging, and data governance features necessary for securely storing sensitive healthcare and claims information.
How quickly can organizations see return on investment from implementing this solution?
Many organizations see measurable improvements within weeks of pilot deployment, with 70-90% reductions in processing time per claim and lower error rates leading to faster reimbursement and reduced rework costs, typically resulting in positive ROI within months.
By combining Bedrock Data Automation and AgentCore with AWS HealthLake, healthcare organizations can transform claims processing from a manual, error-prone burden into a scalable, intelligent operation that improves both efficiency and decision-making.
Continue Learning
Comments
Sign in to join the conversation