Extract Data with On-demand and Batch Pipelines Dynamically
AWS published an engineering guide for an intelligent document processing pipeline on Amazon Bedrock that lets a business choose speed or savings for each document. On-demand inference returns extracted fields within seconds for urgent work, while batch inference runs documents in bulk at a price 50% lower than the on-demand path. With parallelism turned on, the batch pipeline handles 1,000 documents within 15 minutes and uses Claude Sonnet 4 to read the pages.
Key Takeaways
- The pipeline offers two modes so each document goes through the route that fits it: on-demand for rush jobs, batch for large backlogs.
- Batch inference on Amazon Bedrock costs 50% less than on-demand inference, giving teams a direct lever to cut spend on bulk work.
- Claude Sonnet 4 (model ID anthropic.claude-sonnet-4-20250514-v1:0) reads the scanned pages and returns structured data fields.
- The model and prompt are selected per document, so one workflow serves many document formats without a separate build for each.
- The example targets land lease PDFs from Texas counties, turning scanned legal records into usable data fields.
- The full stack deploys through AWS CloudFormation and runs on standard AWS services such as SQS, Lambda, S3, and DynamoDB.
Stats & Key Facts
- #50% lower cost for batch inference on Amazon Bedrock compared to the on-demand pipeline.
- #1,000 documents processed within 15 minutes in the batch pipeline with parallelism enabled.
- #100 records is the minimum batch size required to run a Bedrock batch inference job.
- #20 images is the maximum Claude Sonnet 4 accepts per multimodal call, so longer files split into 20-page chunks.
- #50 prompts per region and 10 versions per prompt are the Bedrock Prompt Management service limits noted in the guide.
On-demand versus batch: trading speed for cost per document
The design splits work into two lanes so each document follows the path that suits its urgency.
- ›On-demand inference processes documents one at a time and returns extracted fields within seconds, fitting requests where a person or system is waiting on the result.
- ›Batch inference groups many documents into asynchronous jobs, which suits large backlogs where immediate turnaround is not needed.
- ›The batch route costs 50% less than on-demand, so the choice between the two is a direct cost decision for each piece of work.
- ›A business is not locked into one approach; rush items flow through on-demand while bulk volume moves through batch.
Batch throughput of 1,000 documents in 15 minutes
Scheduled processing trades live response for higher volume at lower cost.
With parallelism turned on through Python multiprocessing, the batch pipeline processes 1,000 documents within 15 minutes. That throughput shows what is available when work is scheduled rather than served live, one request at a time.
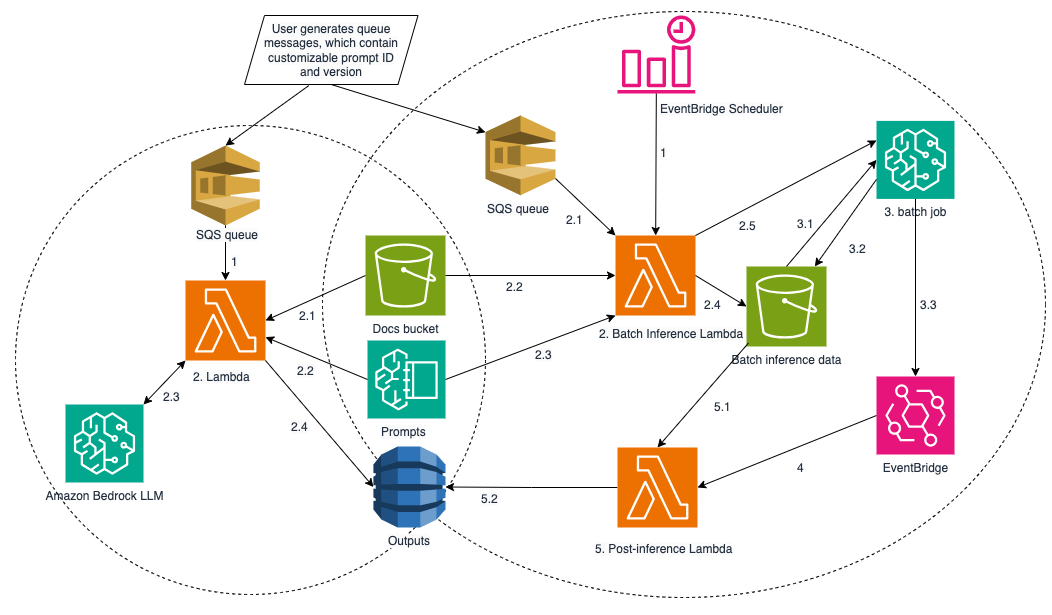
Each batch job needs a minimum of 100 records to run. Amazon EventBridge Scheduler starts the jobs on a defined timetable, so the bulk work runs without a person kicking off each round.
Claude Sonnet 4 reads the pages and returns data fields
The extraction model turns scanned images into structured output.
- ›The solution names Claude Sonnet 4 as the model, with the ID anthropic.claude-sonnet-4-20250514-v1:0.
- ›Each PDF is converted to PNG images before the model reads it, since the model works from page images rather than raw text.
- ›Claude Sonnet 4 accepts a maximum of 20 images per multimodal call, so files longer than 20 pages are split into chunks of 20 pages or fewer.
- ›AWS calls the model through the Bedrock Converse API and parses the returned JSON into data fields.
Per-document model and prompt selection for mixed formats
One workflow handles many document layouts by choosing instructions at the document level.
Each incoming message carries a document ID, a model ID, and a prompt ID with version, plus the file's location in storage. The pipeline reads those values and picks the right model and prompt for that single document, so different formats route to different instructions inside the same workflow.
Amazon Bedrock Prompt Management stores the tailored prompts and their versions. Land lease records arrive as numbered lists, tables, and drawings, so a prompt built for one layout would miss fields in another. Selecting the prompt per document lets the system read each format correctly without a separate build for each one.
Land lease records from Texas counties as the example use case
The guide grounds the design in a real records-extraction problem.
- ›The use case targets organizations sitting on large volumes of scanned land lease PDFs that need their contents turned into usable data.
- ›The example pulls records from Texas counties including Winkler, Andrews, and Sutton.
- ›Extracted fields include tract details such as state, county, abstract number, survey type, section, range or block, and quarter designations.
- ›Results and model performance metrics land in a database table for downstream use.
The AWS services that move and store the documents
Standard AWS building blocks carry each document from intake to stored result.
- ›Amazon SQS routes documents, using a FIFO queue for the on-demand lane and a standard queue for batch.
- ›AWS Lambda runs the processing logic, including the calls to Bedrock and the pre- and post-processing steps.
- ›Amazon S3 stores the source PDFs, the JSONL job files, and the inference outputs.
- ›Amazon DynamoDB holds the extracted attributes and model performance metrics.
- ›AWS CloudFormation deploys the full stack, so a team stands up the whole pipeline from one template.
What the design means for a non-technical buyer
The takeaway is a clear cost lever tied to how fast each document needs an answer.
The core idea is simple: pay more for speed only when speed matters. Route rush work through on-demand inference and push the bulk through batch to cut Bedrock spend by half on that volume. The system decides per document, so the savings do not require a separate workflow for each format.
For an organization with hundreds of thousands of scanned legal or property records, the design turns a manual reading task into structured data fields that downstream systems use. The reference to a deployable CloudFormation stack signals this is meant as a working blueprint, not only a concept.
Frequently Asked Questions
What is the difference between on-demand and batch inference here?
On-demand inference processes one document at a time and returns results within seconds, which fits urgent work. Batch inference groups many documents into asynchronous jobs that run on a schedule and costs 50% less, which fits large backlogs.
How much does the batch option save?
Batch inference on Amazon Bedrock costs 50% less than the on-demand pipeline for the same work. Routing bulk volume through batch cuts Bedrock spend on that volume by half.
Which AI model does the pipeline use?
It uses Claude Sonnet 4, with the model ID anthropic.claude-sonnet-4-20250514-v1:0. The model reads page images and returns structured data fields.
Why are documents split into 20-page chunks?
Claude Sonnet 4 accepts a maximum of 20 images per multimodal call. Since each page is converted to an image, files longer than 20 pages are split into chunks of 20 pages or fewer before processing.
What problem does the example solve?
It extracts structured data from scanned land lease PDFs in Texas counties such as Winkler, Andrews, and Sutton. The pipeline turns fields like county, abstract number, and survey type into usable data.
The pipeline gives businesses a single cost lever for document extraction: route urgent items through on-demand inference and push bulk volume through batch to cut Bedrock spend by half. With Claude Sonnet 4 reading the pages and per-document prompt selection, one workflow handles many record formats from a deployable AWS stack.
Continue Learning
Comments
Sign in to join the conversation