Fine-tune Amazon Nova models for accurate email data extraction
Amazon Nova models can be fine-tuned using SageMaker to extract email data with high accuracy and efficiency. This approach teaches models to recognize specific data patterns in your organization's emails, achieving up to 94.77% extraction accuracy while cutting costs in half compared to base models.
Key Takeaways
- Fine-tuning Amazon Nova models enables recognition of organization-specific email data patterns and formats
- SageMaker provides the infrastructure needed to customize models for precise field distinction and extraction
- Achieves 94.77% extraction accuracy on email data through targeted model training
- Reduces operational costs by 50% compared to using untuned base models
- Fine-tuned models process information more efficiently by learning your exact data requirements
Stats & Key Facts
- #94.77% extraction accuracy achievable with fine-tuned Amazon Nova models
- #50% cost reduction compared to base model alternatives
Why Fine-tuning Matters for Email Data Extraction
Standard AI models struggle with the nuances of email data because they lack exposure to your organization's specific formats and terminology.
- ›Generic models cannot reliably identify your company's unique email fields and data structures
- ›Emails contain ambiguous information where similar fields require domain knowledge to distinguish correctly
- ›Off-the-shelf models waste computational resources processing irrelevant information in emails
- ›Fine-tuning teaches models the exact patterns they need to recognize in your email ecosystem
How Amazon Nova Models Learn Your Data Patterns
Fine-tuning with Amazon SageMaker works by exposing Nova models to representative samples of your email data.
- ›Models learn to identify consistent patterns in how your organization structures and labels email information
- ›The training process strengthens the model's ability to recognize field boundaries and content types specific to your use case
- ›Repeated exposure to your data creates mental models that distinguish between commonly confused fields like sender name vs. sender email
- ›Incremental learning allows the model to improve performance while minimizing resource overhead
The fine-tuning process leverages transfer learning, where pre-trained Nova models already understand language fundamentals and are simply adapted to your domain. This is far more efficient than training models from scratch and requires significantly less training data than building a model without any foundational knowledge.
SageMaker automates much of the infrastructure complexity, handling data preprocessing, model versioning, and deployment so your team can focus on curating quality training data rather than managing compute resources.
Achieving 94.77% Extraction Accuracy
The precision delivered by fine-tuned Nova models represents a substantial leap forward in email automation reliability.
- ›Extraction accuracy of 94.77% means the model correctly identifies and pulls data from emails with minimal manual correction needed
- ›This accuracy level makes the system practical for production workloads where human review time is limited
- ›Higher accuracy reduces downstream errors that propagate through data pipelines and analytics systems
- ›Model performance improves further with additional training data, allowing continuous refinement over time
Accuracy at this level transforms email extraction from a supplementary tool requiring heavy human oversight into a reliable system that can handle bulk processing. When 95 out of 100 extractions are correct, teams can focus human attention on the small percentage of problematic cases rather than validating every single record.
The remaining 5% error rate typically involves edge cases or anomalies in email formatting. With fine-tuning, teams can add examples of these problematic patterns to their training data and further improve accuracy toward 96% or higher.
Cost Reduction Through Model Efficiency
The 50% cost reduction comes from multiple sources when using fine-tuned models instead of repeatedly querying large base models.
- ›Fine-tuned models are optimized to solve your specific problem, eliminating unnecessary processing of irrelevant information
- ›Smaller, specialized models require less computational power per inference compared to general-purpose large models
- ›Reduced error rates mean fewer re-processing attempts and manual corrections, cutting operational overhead
- ›SageMaker's pricing aligns with efficient resource usage, so optimization directly translates to lower AWS bills
Consider the alternative: sending every email to a large general-purpose language model costs more per request and often requires additional filtering steps to clean up irrelevant outputs. Fine-tuning lets you use a model sized and tuned specifically for email extraction, which processes faster and more cheaply.
Over time, the cost savings compound. An organization processing thousands of emails daily could save tens of thousands of dollars monthly through the combination of reduced token usage, fewer errors requiring human intervention, and faster processing times.
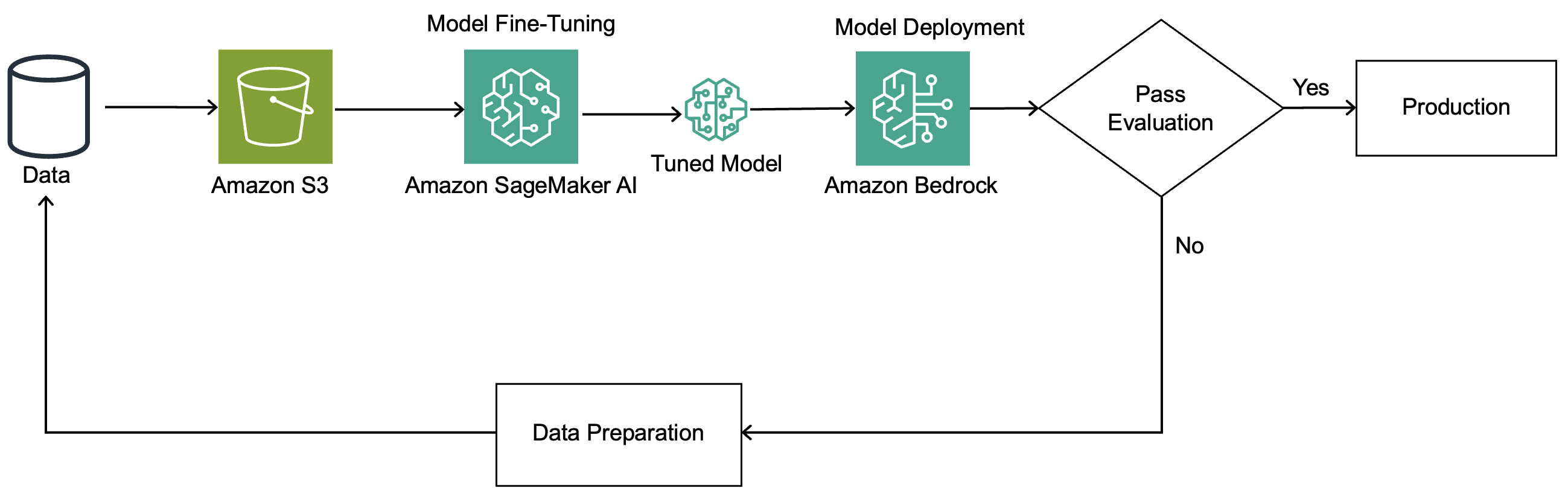
Implementing Fine-tuning with Amazon SageMaker
Getting started with fine-tuning requires preparing your data and configuring SageMaker appropriately.
- ›Prepare a dataset of representative emails with correctly labeled extracted fields
- ›Upload your training data to Amazon S3 for SageMaker to access during fine-tuning jobs
- ›Configure Nova model fine-tuning parameters through SageMaker console or APIs
- ›Monitor training progress and validate the tuned model against hold-out test data before deployment
The quality of your training data directly determines the quality of the resulting model. Emails should be representative of the variety you encounter in production, including edge cases and variations in formatting. Labeling should be consistent and accurate.
SageMaker handles the infrastructure complexity, automatically distributing training across GPUs or other accelerators. You can set it and monitor progress while it runs, then deploy the fine-tuned model to an endpoint for real-time or batch inference.
Distinguishing Between Similar Fields and Content
One of the hardest problems in email extraction is correctly separating related but distinct data points.
- ›Fine-tuning teaches models to distinguish between sender name and sender email address using context
- ›Models learn to separate subject lines, body text, and metadata based on your organization's conventions
- ›Ambiguous fields like dates, amounts, and references are correctly mapped to appropriate columns in your database
- ›Domain-specific vocabulary and abbreviations become meaningful to the model through repeated exposure
For instance, an email might contain multiple email addresses in different contexts: the sender's address, a customer contact, a manager's email, and a support team address. A fine-tuned model learns which field each address belongs to based on position, surrounding context, and patterns in your training data.
This contextual understanding is nearly impossible to achieve with rule-based extraction systems but emerges naturally when you fine-tune neural models on representative data from your environment.
Next Steps and Best Practices
Successfully deploying fine-tuned models requires planning beyond the initial training.
- ›Start with a smaller training dataset and incrementally expand to improve model performance
- ›Establish a pipeline to capture misclassified examples and periodically retrain the model with new data
- ›Monitor production accuracy using held-out test sets to detect performance degradation over time
- ›Document your extracted field definitions clearly so the fine-tuning process has clear targets
Email patterns can evolve as business processes change. Building a feedback loop where production errors are captured and eventually added to training data ensures your model continues to perform well over months and years.
Team collaboration between data scientists, domain experts, and the people who use the extracted data improves training data quality and ensures the model learns patterns that actually matter for your business.
Frequently Asked Questions
What training data do I need to fine-tune Amazon Nova for email extraction?
You need a dataset of representative emails from your organization with correctly labeled extracted fields. Start with 100-500 examples covering various email types and edge cases you encounter. The more diverse and accurate your training data, the better the fine-tuned model will perform.
How long does fine-tuning take with SageMaker?
Fine-tuning duration depends on your dataset size and training configuration, but typically ranges from minutes to a few hours for email extraction tasks. SageMaker provides real-time progress monitoring so you know when your model is ready for testing.
Can I use a fine-tuned Nova model in production immediately after training?
You should validate the fine-tuned model against a held-out test set first to confirm it meets your accuracy requirements. Once validated, SageMaker makes it easy to deploy to an endpoint for production workloads handling real-time or batch inference.
What if my email formats change over time?
Capture examples of new or changed email formats in production, then periodically retrain your model with the updated training data. This continuous improvement approach keeps your model accurate as business processes evolve.
Will fine-tuning work for my industry-specific email terminology?
Yes, fine-tuning specifically teaches models your domain's vocabulary and conventions. By training on your own emails containing industry-specific terms and patterns, the model learns to recognize and extract these correctly.
Fine-tuning Amazon Nova models with SageMaker transforms email data extraction from a labor-intensive manual process into a highly accurate, cost-effective automation system.
Continue Learning
Comments
Sign in to join the conversation