How NVIDIA's Inference Software Stack Powers the Lowest Token Cost
NVIDIA's inference software stack is designed to minimize token cost-the expense of generating each AI output token-by optimizing GPU utilization, power efficiency, and latency simultaneously. As organizations scale from AI experiments to production deployments, cost-per-token has become the critical metric replacing raw chip performance, and NVIDIA's integrated hardware-software approach addresses this shift.
Key Takeaways
- Cost-per-token is now the primary metric organizations use to evaluate AI infrastructure, replacing peak chip specifications and raw performance measures.
- NVIDIA's inference stack is codesigned across GPUs, CPUs, networking, and systems to optimize token throughput per dollar and per watt.
- The software ecosystem, including open-source tools and community contributions, plays a key role in reducing token costs and improving deployment efficiency.
- Production AI factories require balancing three constraints: cost per token, power consumption per token, and latency guarantees.
- Integrated hardware-software codesign enables organizations to achieve lower inference costs than point solutions alone.
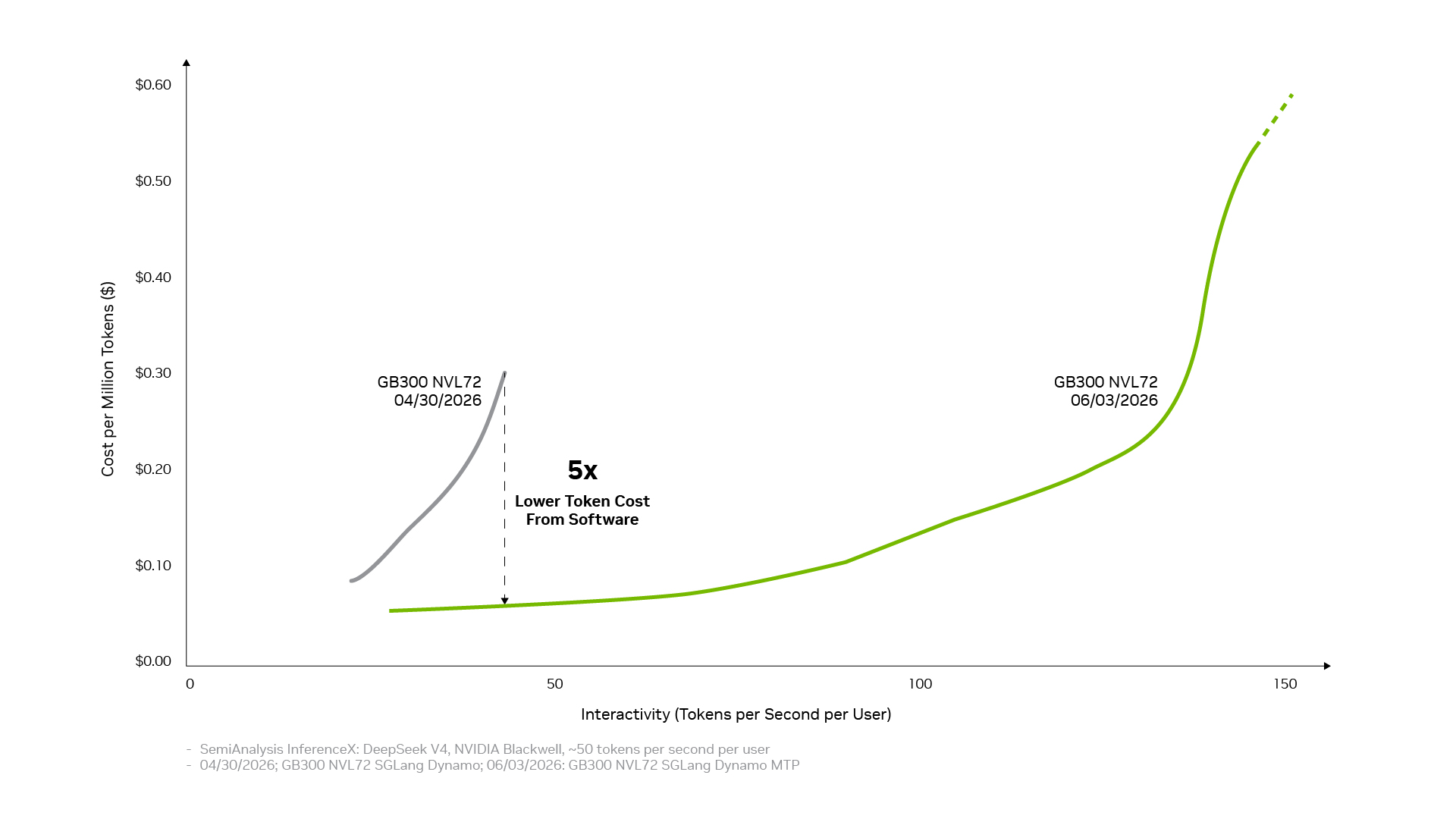
The Shift from Peak Performance to Cost Efficiency
Enterprise AI strategies have fundamentally changed as deployments move from proof-of-concept to scaled production.
- ›Early AI pilot programs focused on model capabilities and peak GPU specs; production factories prioritize cost per token delivered.
- ›Organizations now measure success by their ability to serve millions of inference requests profitably within strict latency windows.
- ›Cost-per-token encompasses three dimensions: dollar cost, power consumption, and response latency-all must be optimized simultaneously.
- ›This shift reflects the maturation of AI from experimental technology to core business infrastructure that must demonstrate ROI.
NVIDIA's Codesigned Hardware-Software Approach
Rather than optimizing software independently of hardware, NVIDIA develops its inference stack with tight integration across the entire platform.
- ›NVIDIA GPUs, CPUs, and networking components are engineered together to maximize inference efficiency at each layer of the stack.
- ›Codesign eliminates mismatches between hardware capabilities and software assumptions, reducing wasted compute cycles.
- ›System-level optimization ensures that data movement, memory bandwidth, and compute kernels work in concert rather than in isolation.
- ›This vertical integration allows NVIDIA to make trade-offs that point solutions cannot, such as accepting slightly lower peak performance to achieve better sustained token throughput.
The codesigned approach differs fundamentally from purchasing separate GPU accelerators and then layering inference software on top. Instead, NVIDIA optimizes the entire path from data ingestion through token generation. This holistic view reveals bottlenecks that component-level optimization would miss, such as congestion between GPU memory and the network, or suboptimal CPU scheduling of inference requests.
Open Source Ecosystem as a Cost Multiplier
NVIDIA's inference stack is strengthened by a broad ecosystem of open-source projects and community contributions.
- ›Open-source frameworks and libraries allow organizations to implement custom optimizations without waiting for vendor updates.
- ›Community contributions identify new inference patterns and edge cases, leading to continuous improvements in token efficiency.
- ›Open standards reduce vendor lock-in and enable organizations to adopt best practices across heterogeneous deployments.
- ›Shared optimization knowledge accelerates industry-wide progress in reducing inference costs, benefiting all participants.
The open-source ecosystem surrounding NVIDIA's stack includes inference libraries, quantization tools, model optimization frameworks, and monitoring utilities developed by organizations across academia and industry. This collaborative environment creates a feedback loop: as users encounter real-world bottlenecks, they contribute solutions that benefit the broader community. Over time, these contributions compound into significant improvements in cost-per-token efficiency that proprietary solutions alone could not achieve.
Balancing Cost, Power, and Latency
Production AI factories operate under multiple constraints that must be satisfied simultaneously.
- ›Cost-per-token reduction often requires running GPUs at lower power levels or with higher utilization, which can increase latency unless carefully managed.
- ›Latency requirements vary by application: real-time conversational AI may tolerate only 100-200ms total response time, while batch processing allows minutes.
- ›Power constraints become critical in large-scale deployments where energy costs represent 30-50% of infrastructure expense.
- ›NVIDIA's stack provides tools to profile and optimize these trade-offs, helping organizations find the Pareto frontier for their specific use case.
A naive approach to cost reduction-simply running inference on older, cheaper GPUs-fails when latency or throughput requirements force larger batch sizes or multiple inference passes. NVIDIA's software stack includes profiling and auto-tuning tools that help organizations navigate these trade-offs. For example, quantization to lower precision reduces memory footprint and increases throughput per watt, but may require techniques like calibration to maintain accuracy. The stack provides these techniques in integrated form, so users can experiment with different configurations and measure cost-per-token across the three dimensions.
Integration Across the Full Stack
NVIDIA's inference optimization spans GPU kernels, memory management, networking, CPU scheduling, and system-level orchestration.
- ›GPU-level optimizations include custom kernels for attention mechanisms, embedding lookups, and other inference bottlenecks specific to large language models.
- ›Memory management techniques reduce data movement between GPU memory, system RAM, and storage, directly lowering power consumption.
- ›Networking optimizations reduce latency and overhead for distributed inference across multiple GPUs or nodes.
- ›CPU scheduling and orchestration software ensures that GPUs remain saturated with work, avoiding idle cycles that inflate cost-per-token.
The full-stack approach means that improving inference efficiency is not left to application developers; it is built into the platform from the ground up. For instance, NVIDIA's inference libraries include fused operations that combine multiple neural network layers into a single GPU kernel, reducing memory bandwidth requirements and kernel launch overhead. CPU-GPU communication is carefully pipelined to hide latency. Networking libraries optimize multi-GPU and multi-node communication patterns common in inference clusters. When these optimizations are integrated into a single coherent stack rather than scattered across separate tools, their combined effect is multiplicative rather than additive.
Practical Impact on Production Deployments
Organizations deploying AI at scale see tangible benefits from NVIDIA's integrated approach.
- ›Reduced token cost directly translates to lower per-user expense, enabling profitability at higher per-user inference volumes.
- ›Improved power efficiency reduces cooling and facility costs, which compound over multi-year deployments.
- ›Predictable latency behavior enables service level agreement guarantees, essential for production AI services.
- ›Faster time to optimization allows organizations to focus engineering resources on model improvement rather than infrastructure tuning.
In practice, organizations that adopt NVIDIA's integrated inference stack report cost-per-token reductions of 2-3x compared to generic software stacks running on the same hardware. This improvement comes not from faster chips, but from better utilization of the compute resources already available. When an organization can serve 2-3x more tokens per dollar per watt, the business impact is substantial: it can either reduce prices to gain market share, increase profit margins on existing revenue, or both. The open-source ecosystem multiplies this advantage further by enabling continuous optimization as deployment patterns evolve.
Looking Forward: Continuous Optimization
Cost-per-token optimization is not a one-time effort but an ongoing process as models, workloads, and hardware evolve.
- ›New model architectures and inference patterns emerge regularly, requiring corresponding software optimizations.
- ›Hardware evolution, including new GPU generations and specialized inference accelerators, demands continuous software updates.
- ›Organization-specific use cases benefit from domain-specific optimization, supported by NVIDIA's flexible stack architecture.
- ›The open ecosystem ensures that cutting-edge optimization techniques developed by researchers and practitioners reach production users quickly.
Frequently Asked Questions
What is cost-per-token and why does it matter?
Cost-per-token is the expense to generate a single token of AI output, measured in dollars per token, watts per token, or milliseconds of latency per token. It matters because it directly determines whether an AI service can be profitable and scalable in production, replacing earlier metrics focused only on peak chip performance.
How does NVIDIA's codesigned approach lower token costs compared to generic software?
Codesign ensures that NVIDIA GPUs, CPUs, networks, and software work together optimally, eliminating bottlenecks that separate tools miss. Custom GPU kernels, efficient memory movement, and integrated scheduling all contribute to 2-3x cost-per-token reductions on the same hardware.
What role does the open-source ecosystem play in NVIDIA's inference stack?
The open-source ecosystem provides continuous community contributions that identify and optimize new inference patterns, reduce vendor lock-in, and accelerate industry-wide progress in cost-per-token efficiency.
How can organizations balance cost, power, and latency requirements?
NVIDIA's stack provides profiling and auto-tuning tools that help organizations explore trade-offs between these three dimensions. Techniques like quantization and kernel fusion enable lower cost and power at acceptable latency for specific use cases.
Is cost-per-token optimization a one-time effort?
No, it is ongoing. New model architectures, hardware generations, and use cases constantly emerge, requiring corresponding software updates. The open ecosystem ensures that cutting-edge optimizations reach production users continuously.
NVIDIA's integrated hardware-software approach to inference optimization proves that cost-per-token is not just a metric but a design philosophy that shapes how production AI infrastructure should be built.
Continue Learning
Comments
Sign in to join the conversation