Report: GKE Inference Gateway delivers up to 92% faster AI responses
Google Cloud reports that its GKE Inference Gateway cut the time an AI model takes to start responding by 92.8% compared with Amazon's Kubernetes service in an independent benchmark. The gateway routes AI requests to the exact server already holding the relevant data in memory, using a method called prefix caching. The same test showed 15.7% higher throughput and 62.6% lower delay between words as they stream out. Snap reported reusing cached data on 75 to 80% of requests in its own production setup.
Key Takeaways
- GKE Inference Gateway is Google's traffic router for AI workloads on Kubernetes; it sends each request to the server best prepared to answer it instead of spreading requests evenly across servers.
- An independent benchmark by Principled Technologies pitted Google's GKE against Amazon EKS using the Llama 3.1 8B model on identical NVIDIA A100 hardware.
- Prefix caching stores the model's work on long, repeated parts of a prompt, such as system instructions or pasted documentation, so the model skips re-reading them on the next request.
- Snap reported prefix cache hit rates of 75 to 80% in production, meaning most requests reused already-processed context.
- The technology builds on llm-d, an open-source project, which let Snap connect it to its existing Envoy service mesh without heavy rework.
- Google frames the feature for document Q&A with retrieval, multi-turn chat, and real-time uses like fraud detection and coding assistants.
Stats & Key Facts
- #92.8% faster time to first token (188.36 ms versus 2,624.73 ms) in the independent benchmark
- #15.7% higher throughput (7,169.21 versus 6,042.05 output tokens per second)
- #62.6% lower inter-token latency (30.20 ms versus 81.03 ms)
- #75 to 80% prefix cache hit rates reported by Snap in production
- #Test ran Llama 3.1 8B Instruct on 8 NVIDIA A100 40GB GPUs
- #Static documentation prefixes of 10,000-plus words pinned in cache in the RAG example
What GKE Inference Gateway changes about serving AI models
The gateway replaces a basic load-balancing method with one that understands what each AI server is ready to do.
Most web traffic gets spread across servers in a simple rotation, sending each new request to the next machine in line. That works for ordinary websites but wastes effort for AI models, because the chosen server often has to redo expensive setup work before it answers.
GKE Inference Gateway instead reads live metrics from each model server and routes based on which one is primed to respond fastest. Google describes it as a native extension of the existing GKE Gateway, so teams already running on Google Kubernetes Engine add the capability rather than rebuilding their stack.
The goal is to keep expensive accelerator chips busy with real work instead of repeated recomputation, which lowers both wait times and cost for the same hardware.
How prefix caching skips repeated work
Prefix caching is the core idea behind the speedups Google reports.
- ›A prompt often starts with a long, fixed block: system instructions, business rules, or pasted reference material.
- ›The model normally re-reads that whole block every time, which Google calls a thinking tax on the GPUs and TPUs.
- ›Prefix caching stores the model's processed version of that block, known as the KV cache, in server memory.
- ›The gateway matches an incoming request to the exact server already holding the matching cached data.
- ›The model then only computes the short, changing part of the request, such as the user's new question.
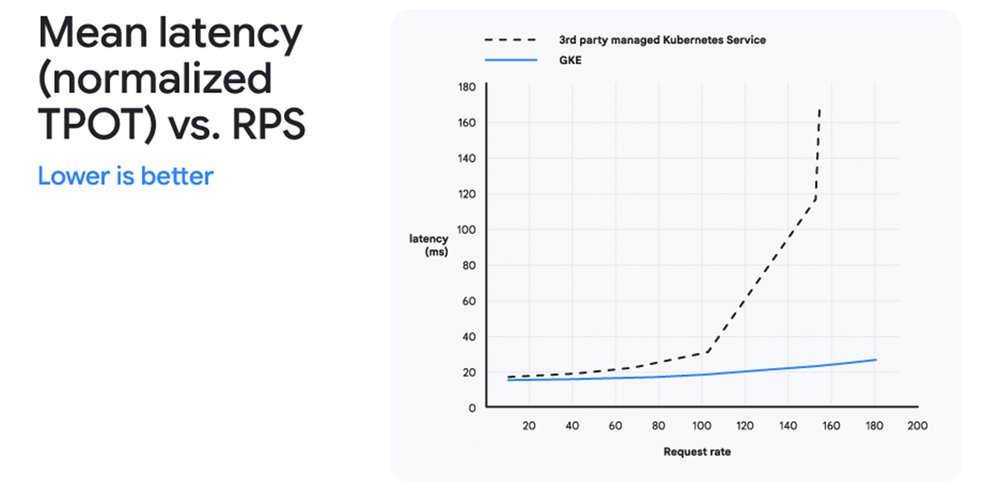
The Principled Technologies benchmark versus Amazon EKS
The headline numbers come from an outside firm, not from Google's own lab.
Principled Technologies ran the comparison between GKE with the Inference Gateway and Amazon Elastic Kubernetes Service using a standard HTTP load balancer. Both setups served the same Llama 3.1 8B Instruct model on eight NVIDIA A100 40GB GPUs, so the hardware was held equal.
On that test, Google's setup started responding in 188.36 milliseconds versus 2,624.73 milliseconds on the Amazon configuration, the 92.8% gap in time to first token. It also pushed 7,169.21 output tokens per second against 6,042.05, and trimmed the delay between streamed words from 81.03 to 30.20 milliseconds.
Principled Technologies noted the gains matter most for workloads where requests share common prefixes or benefit from cache locality, such as document Q&A, multi-turn conversations, and template-based generation.
Snap's production results and the llm-d open-source layer
A named customer reported its own numbers, lending the claims real-world weight.
Snap integrated the technology into its production AI infrastructure for high-volume inference. Vinay Kola, a senior engineering manager at Snap, reported prefix cache hit rates ranging up to 75 to 80%, meaning the system reused already-processed context on most requests.
Snap credited llm-d, the open-source project underneath the routing feature, for letting it connect cleanly to its existing Envoy-based service mesh. The open nature of the project mattered because it avoided locking Snap into a single vendor's plumbing.
Three use cases Google highlights for business teams
Google ties the feature to common enterprise patterns rather than abstract benchmarks.
- ›Documentation and codebase Q&A with retrieval: an entire API reference or company wiki stays pinned as a cached prefix, so the model answers questions without re-reading thousands of lines each time.
- ›Multi-turn chat: a fixed customer-service persona and business rules stay cached on the server, supporting thousands of simultaneous sessions without reprocessing the same setup.
- ›Real-time applications: support agents, coding assistants, and sub-second fraud detection models, where shaving the startup delay changes whether a response feels instant.
Why the wait-time number matters more than it looks
The 92.8% figure points at a specific moment users notice most.
Time to first token measures how long a person waits before any answer starts appearing on screen. That pause shapes whether an AI assistant feels responsive or sluggish, more than raw throughput does, because users react to the first sign of progress.
Cutting that pause from over two and a half seconds to under a fifth of a second, as the benchmark reports, is the difference between a noticeable lag and a near-instant reply. For high-traffic products, the throughput and per-token gains then compound across many concurrent users, which is where the cost savings on accelerator hardware show up.
Frequently Asked Questions
What is GKE Inference Gateway in plain terms?
It is Google's smart traffic router for AI models running on Google Kubernetes Engine. Instead of spreading requests evenly across servers, it sends each request to the server already prepared to answer it fastest, which lowers wait times and keeps expensive chips busy.
What is prefix caching and why does it speed things up?
Prefix caching saves the model's processed work on the long, repeated front part of a prompt, such as system instructions or pasted documents. On the next request the model skips re-reading that block and only computes the new part, so it responds much faster.
Who ran the benchmark and what was compared?
Principled Technologies, an independent testing firm, compared Google's GKE with the Inference Gateway against Amazon EKS using a standard load balancer. Both ran the Llama 3.1 8B model on identical eight-GPU NVIDIA A100 hardware.
What did Snap actually report?
Snap said it reached prefix cache hit rates of 75 to 80% in its production AI infrastructure, meaning most requests reused already-processed context. Snap connected the feature through the open-source llm-d project and its existing Envoy service mesh.
What kinds of applications benefit most?
Workloads where many requests share a large common chunk of text, such as document Q&A with retrieval, multi-turn customer chat, and real-time tools like coding assistants and fraud detection, where a faster first response matters most.
Google's pitch is that smarter routing plus prefix caching turns slow, costly AI serving into fast, production-grade responses on the same hardware. The independent benchmark against Amazon EKS and Snap's reported cache hit rates give the claims outside support.
Continue Learning
Comments
Sign in to join the conversation