AI News and Blog Articles
Curated updates from the most trusted sources in artificial intelligence. Stay ahead without the noise.
Top AI News
Hand-picked stories worth reading right now1,711 articles found · page 5 of 18

Sharpen the Sword, Skip the Downloads - 'Onimusha: Way of the Sword' Is Coming to GeForce NOW
Onimusha: Way of the Sword is coming to GeForce NOW at launch, with the playable demo available this week. It's joined by Denshattack! rolling in with five new games arriving in the cloud. Plus, GeForce NOW officially launches in India, moving from beta to public availability - meaning gamers can sign up without a waitlist. [...]

Digital Surveillance Reshapes Fishery Enforcement in Indonesia
In the eastern Indian Ocean, south of Java in the vast sea stretching toward Australia, a fishing vessel slightly alters its course while operating near the boundary of its authorized fishing ground. Nothing appears unusual on deck. Nets remain in the water. Engines maintain a steady speed. To the crew, it is an ordinary day at sea. Yet hundreds of kilometers above, satellites continuously record the vessel's position. At Indonesia's Marine and Fisheries Resources Surveillance Station, in Cilacap, where I work, a monitoring platform receives the signal and automatically compares it against fis

Why the best time to invest in Ukraine is now
Roman Sulzhyk, Founding Partner of Ukrainian investment fund Resist.UA, has a message for the world when it comes to investing in the Ukrainian startup ecosystem: "If you wait until after the war, yo...

The Billion-Dollar Seed Isn't The Deal You Think It Is
Despite attention-grabbing AI mega-seed rounds, historical data shows that very large first financings rarely produce venture-scale returns because high entry valuations limit investor upside. Instead, argues guest author Ellie McDonald, the strongest venture outcomes have typically come from capital-efficient startups that raised modest early rounds.

China And AI Lead Asia's Startup Funding To Multiyear Peak In Q2
Overall, investors poured $42.8 billion into startup funding rounds across all of Asia in Q2 2026, per Crunchbase data. Led by China's $7.4 billion DeepSeek raise, that's by far the highest quarterly total in more than three years.
Fine-Tuning vs. RAG: When To Use Each for Production LLMs
Explore fine-tuning versus RAG to understand how they differ, when each approach works best, and why many production LLM systems use both.

Three insights you may have missed from theCUBE's coverage of RAISE Summit
Agentic inference is reshaping the center of gravity in AI infrastructure. What began as a race to scale training has shifted into a phase defined by expanding context windows, memory‑augmented reasoning and the need to keep graphics processing units continuously fed with data. As enterprises push deeper into agentic systems, storage has moved into the [...] The post Three insights you may have missed from theCUBE's coverage of RAISE Summit appeared first on SiliconANGLE.

QumulusAI's direct listing: Accelerating the neocloud for enterprise AI
Neocloud provider QumulusAI said today that it will starting trading Thursday as a publicly traded company on Nasdaq under the ticker symbol QMLS via a direct listing. For those unfamiliar with the process, the typical initial public offering takes time and requires an investment banker, whereas a direct listing does not create new shares. Instead, existing [...] The post QumulusAI's direct listing: Accelerating the neocloud for enterprise AI appeared first on SiliconANGLE.

Mira Murati's Thinking Machines drops Inkling, an open-weights model anyone can access
Mira Murati's Thinking Machines Lab Inc. today launched its first foundation model with the release of Inkling, making its full open weights available to developers so they can fine-tune it as they wish. Inkling is the first model fully trained from scratch by Thinking Machines, coming after a year in which the company mostly made [...] The post Mira Murati's Thinking Machines drops Inkling, an open-weights model anyone can access appeared first on SiliconANGLE.
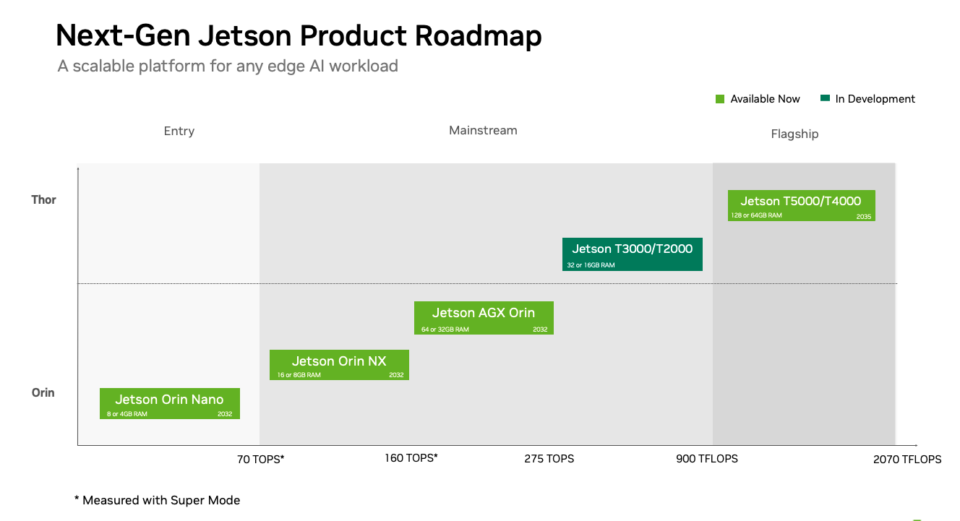
NVIDIA Introduces New Jetson Thor Computers to Advance Mainstream Robotics and Edge AI
General-purpose robots and autonomous machines are moving from research labs to real-world mass-market deployment, creating demand for compact, power-efficient AI supercomputers capable of running foundation models at the edge. To meet that need, NVIDIA today introduced the T3000 and T2000, new modules based on the NVIDIA Thor architecture that enable mass-market robotics and edge AI [...]

Cadence extends its AI agents beyond chips with AuraStack for circuit boards and packaging
Integrated circuit and electronic hardware design company Cadence Design Systems Inc. today announced a new artificial intelligence agent that assists with packaging and system design, the step after silicon has been customized and produced, marking how chips and components get used in electronic devices. AuraStack, a super-agent within the company's Allegro AI studio, provides agentic [...] The post Cadence extends its AI agents beyond chips with AuraStack for circuit boards and packaging appeared first on SiliconANGLE.

Agentic orchestration: Enterprise AI organizations have a deployment problem, not a platform problem - and most are calling chatbots agents
Across 101 enterprises, agent orchestration is consolidating onto model-provider platforms - Anthropic's Claude leads by a wide margin - chosen for the gravity of the underlying model and judged on reliable multi-step execution. But the ambition runs well ahead of the reality: most deployed "agents" are still chatbot wrappers, the control plane enterprises expect is deliberately hybrid to avoid lock-in, and real-time fiscal control over token burn remains the exception. This wave of VentureBeat Pulse Research examines enterprise agent orchestration: which platforms enterprises run on, what dri

AWS adds AI-assisted product listing service to its Marketplace portfolio
Product listings in AWS Marketplace gained new AI-based features last month in anticipation of continued growth in the use of enterprise agents. Amazon Web Services Inc. unveiled AI-assisted product listings in Product Assistant chat, a feature that helps independent software vendors and consulting partners develop comprehensive product listings for AWS Marketplace using existing digital assets. [...] The post AWS adds AI-assisted product listing service to its Marketplace portfolio appeared first on SiliconANGLE.

Construction robot startup Monumental reels in $32M
Monumental BV, a Dutch startup that operates a fleet of bricklaying robots, has raised $35 million in funding. Khosla Ventures led the Series B investment. Monumental stated in its funding announcement today that existing backers Plural and Hummingbird chipped in as well. Monumental uses robots to construct the walls of homes, schools and other buildings. [...] The post Construction robot startup Monumental reels in $32M appeared first on SiliconANGLE.

Stripe's Acquisition Pace Has Accelerated In The Past Five Years, But Nothing Comes Close To Its Reported $53B PayPal Bet
Payments giant Stripe and private equity firm Advent International have teamed up to make an offer to buy troubled PayPal in a deal valued at more than $53 billion, Reuters reported Wednesday.
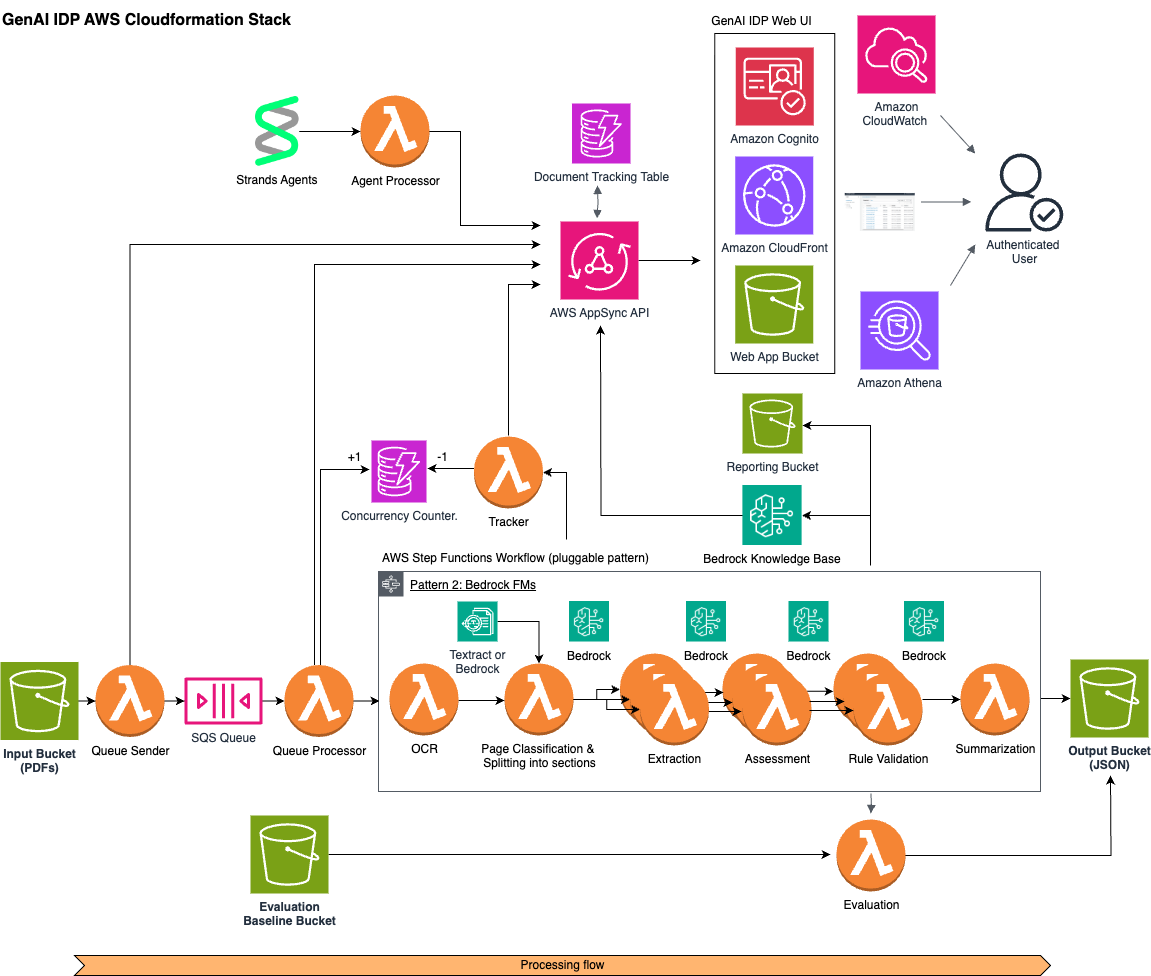
Built Technologies builds an AI-powered document intelligence solution on AWS to power agents across real estate finance
Built partnered with the AWS Generative AI Innovation Center (GenAIIC), AWS Partner AND Digital, and AWS account teams to create a scalable, AI-powered document processing engine that can classify, split, extract, evaluate, and reason over complex real estate finance documents. It reduces workflows that previously took days to minutes, supports hundreds of document types, and gives technical teams and industry experts a shared environment for building and improving document processors.
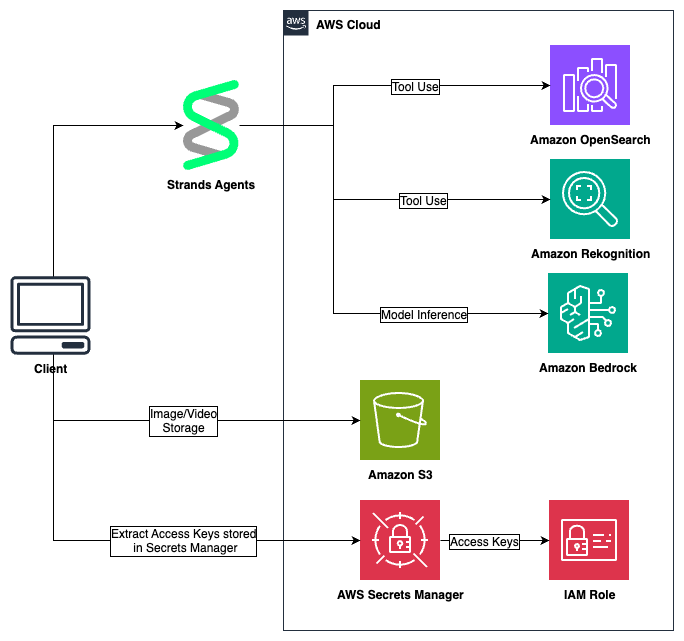
Agentic vision: Building visual intelligence with Amazon Bedrock and MCP servers
In this post, we walk you through the Computer Vision MCP Server, which illustrates this approach, representing how AI systems can process visual information and make intelligent decisions through a single, standardized interface. This convergence transforms what was once a complex integration challenge into a streamlined process, making AI capabilities accessible to a broader range of applications and developers.
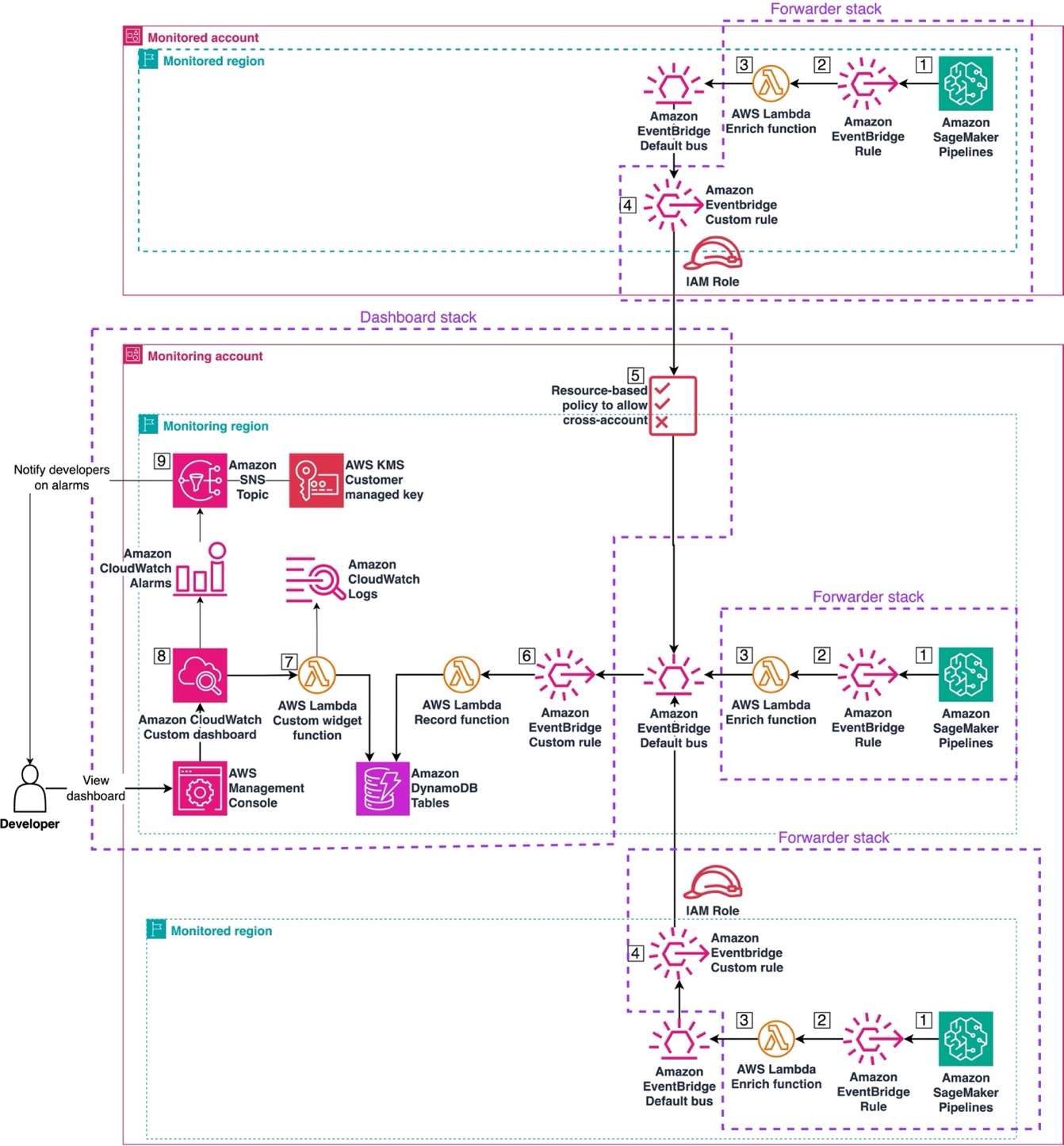
Monitor Amazon SageMaker Pipelines cross-account with custom Amazon CloudWatch dashboards
In this post, we present a solution designed to centralize the monitoring of SageMaker Pipelines across AWS accounts and Regions using Amazon CloudWatch custom dashboards. The accompanying GitHub repository provides a customizable AWS Cloud Development Kit (AWS CDK) example of the required infrastructure.

Atlassian evolves Jira into an orchestration hub for developers and AI agents
Atlassian Corp. today announced it is expanding Jira with updates that will help developers prepare, distribute and track work performed by artificial intelligence agents. The company's new Jira Planner helps turn incomplete project ideas into technical specifications, while its Jira Coding Agent and integrations with third-party agents transform work items into requests. With automation rules [...] The post Atlassian evolves Jira into an orchestration hub for developers and AI agents appeared first on SiliconANGLE.

Perplexity launches secure sandbox to make its AI agents secure and powerful
Perplexity AI Inc. today introduced a new feature that takes its current agentic artificial intelligence service, Computer, to perform better with greater security. The company introduced SPACE, a sandbox platform designed to allow its AI agent to act with its full capabilities, while providing the highest level of security for agentic systems. Perplexity Computer can [...] The post Perplexity launches secure sandbox to make its AI agents secure and powerful appeared first on SiliconANGLE.

The First Chatbot's Multiple Personalities
ELIZA is remembered as the world's first AI star, a kindly therapist in chatbot form that gently probed users' worries. Even its creator, Joseph Weizenbaum, was surprised by the warm reception given to his experiment in human-machine interaction. For some, it heralded an age of automated psychotherapy, while others believed the program demonstrated sentience, a fallacy soon known as the "ELIZA effect." Based on published descriptions, ELIZA has been implemented on many different computers, but only recently has the actual source code been unearthed from MIT's archives. In Inventing ELIZA: How
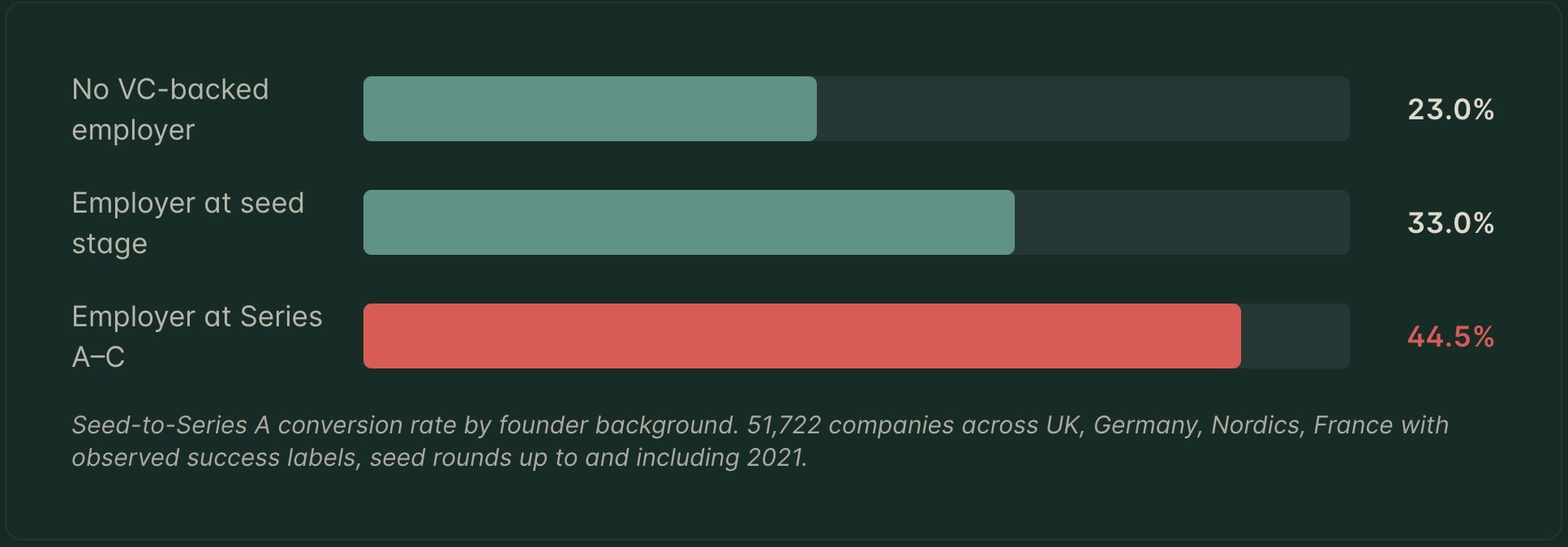
Scaling startups create Europe's most successful founders, Antler finds
Research published today by global early-stage VC firm Antler reveals that the single most important decision a founder can make is which company they work at before building their own, and specifical...

Chipmaker Axelera releases Voyager Wingman to speed edge AI development
Edge artificial intelligence chip company Axelera AI B.V. today publicly released Voyager Wingman, an AI assistant that lets developers build and troubleshoot applications for its edge chips by typing plain-language requests instead of digging through documentation. The tool connects to the company's Voyager software development kit and its full documentation set. Developers can describe the [...] The post Chipmaker Axelera releases Voyager Wingman to speed edge AI development appeared first on SiliconANGLE.

This AI Folds DNA Into Mini Masterpieces
Shaped like dogs, stars, and the Mona Lisa, you could mistake these DNA structures for fun-shaped macaroni if they weren't only nanometers wide. South Korean scientists made the constructions using a technique called DNA origami, which can bend genetic material into any form. Designing DNA strands so they'll fold into a specific shape typically requires tedious manual work, but the researchers behind the playful fabrications have developed a shortcut using generative AI. The AI model, called Generative SNUPI (short for Structured Nucleic Acids Programming Interface, and, yes, inspired by the d
Emergent emerges as the latest AI unicorn after raising $130M in funding
Emergent Labs Inc., a vibe coding startup that aims to give nontechnical users the tools to develop production-grade enterprise software, has closed on its third major round of funding in just 10 months after raising $130 million. The Series C round, announced today, was led by Creaegis and Claypond and saw participation from Khosla Ventures, [...] The post Emergent emerges as the latest AI unicorn after raising $130M in funding appeared first on SiliconANGLE.

AGI raises $70M to buy up and transform insurance firms into AI-native operations
A startup called American Growth Insurance said today it has raised almost $70 million in committed equity capital to transform the insurance industry. It plans to do so with an aggressive, technology-focused business model that's quite unlike anything its competitors do. AGI, officially known as AGI Holdings LLC, says it has worked out how to use [...] The post AGI raises $70M to buy up and transform insurance firms into AI-native operations appeared first on SiliconANGLE.
Creatio expands beyond its no-code roots with conversational development tool and AI studio
Creatio Inc. today introduced what it calls a major update to its customer relationship management and workflow platform that enables business users and information technology teams to build, deploy and govern artificial intelligence agents alongside conventional customer workflows. The Creatio 10x release combines the company's CRM applications with new tools for developing personal assistants, deterministic [...] The post Creatio expands beyond its no-code roots with conversational development tool and AI studio appeared first on SiliconANGLE.

AI DevOps startup MyDecisive launches with $12M and open-source SmartHub
Artificial intelligence DevOps startup MyDecisive formally launched today and announced $12 million in new funding to bring to market an open-source foundation for managing observability data and a commercial suite it says can slash what enterprises spend running production systems. Ari Zilka founded MyDecisive in San Francisco in 2023, backed by a long track record [...] The post AI DevOps startup MyDecisive launches with $12M and open-source SmartHub appeared first on SiliconANGLE.
Fintech Funding Surges 23% In H1 2026 As Investors Concentrate Their Bets On AI And Financial Infrastructure
Venture funding into fintech startups climbed nearly 23% year over year in H1 2026, even as deal count fell more than 25%, Crunchbase data shows, a sign that investors are writing fewer, but much larger checks into the sector as they focus on areas such as wealth management, financial infrastructure and enterprise automation. We take a look at the numbers.

Corporate Venture Capital Is Splitting In Two
The wind-downs at PayPal and Fidelity International may look like a retreat, but the data points to a concentration of power at the top of the market that smaller funds will feel first, writes guest author Steve Brotman of Alpha Partners.

NVIDIA and Japan Bring Full-Stack AI and Robotics to Every Industry
Home to leading manufacturers, robotics pioneers and infrastructure builders, Japan is one of the world's centers of AI - building across the full stack with NVIDIA technologies. NVIDIA and its partners in Japan are this week showcasing the AI ecosystem's latest advancements. Check back here for updates. NVIDIA and SEGA Celebrate 30 Years of [...]

Construction automation startup TerraFirma raises $115M
TerraFirma Inc., a startup with a platform that enables construction teams to remotely operate heavy machinery, has raised $115 million in funding. The bulk of the capital arrived in the form of a $100 million Series A round led by Kleiner Perkins. TerraFirma disclosed today that Bain Capital, Definition and more than a half-dozen other [...] The post Construction automation startup TerraFirma raises $115M appeared first on SiliconANGLE.

InstaLILY, a developer of AI teammates that can automate complex, business-specific work, raises $60M
Enterprise automation startup InstaLILY Inc. said today it has closed on a hefty $60 million Series B round of funding that brings its total amount raised to date to almost $100 million. In addition, it launched a new tool that can help companies to quickly build, deploy and then continuously update and maintain software that [...] The post InstaLILY, a developer of AI teammates that can automate complex, business-specific work, raises $60M appeared first on SiliconANGLE.

Google DeepMind CEO Demis Hassabis calls for creation of AI standards body
Artificial intelligence pioneer Demis Hassabis today called for the creation of a standards body focused on regulating frontier models. Hassabis, chief executive of Google DeepMind, proposed in a Substack essay that the U.S. should lead the effort. Axios reported that the executive has held talks about the initiative with the White House, European officials and [...] The post Google DeepMind CEO Demis Hassabis calls for creation of AI standards body appeared first on SiliconANGLE.

New York becomes first US state to impose a data center moratorium
New York became the first state in the U.S. to impose a statewide moratorium on new data centers today after Governor Kathy Hochul signed an executive order pausing state environmental permits for large facilities for up to a year. Executive Order No. 62 took effect on signing and covers hyperscale data centers that draw 50 [...] The post New York becomes first US state to impose a data center moratorium appeared first on SiliconANGLE.