AI News and Blog Articles
Curated updates from the most trusted sources in artificial intelligence. Stay ahead without the noise.
Top AI News
Hand-picked stories worth reading right now52 articles found

HeyDonto launches DFT Labs to pursue physics-based machine learning capabilities
Artificial intelligence startup HeyDonto AI Technology today announced that it has established DFT Labs, a research subsidiary dedicated to pursuing a physics-based framework for machine learning. The launch of the new company follows the publication of the framework's peer-reviewed foundational paper "Data Field Theory: A Geometric Framework for Learning on Riemannian Manifolds with Synthetic Validation [...] The post HeyDonto launches DFT Labs to pursue physics-based machine learning capabilities appeared first on SiliconANGLE.

Why AI Needs a "Genie Coefficient"
Major benchmarks measure what AI can do. None measure whether it does what you mean: the distance between what you ask an AI to do and the unspoken assumptions about how you want the AI to do it. We propose a new metric: the Genie coefficient. There's often a gap between one person's request and another's understanding. Most of the time, we bridge it using general knowledge. For example, if you ask a friend to get you coffee, they'll pour a cup from the pot or buy one from a coffee shop. They won't bring you a bag of raw beans or snatch a cup from a stranger and hand it to you. You never speci

Exploring self-distilled reasoning for supervised fine-tuning with Amazon Nova
In this post, we explore an idea for generating thinking tokens for datasets that lack reasoning traces in SFT customization. We first examine the reasoning suppression problem, then introduce Self-Distilled Reasoning (SDR), validate it across three benchmarks, and provide practical recommendations.

How to Make an Invisible Drone
There are many words that I would never, ever use to describe a drone. Stealthy. Subtle. Whatever the opposite of obnoxious is. Much of this is because of the giant angry bee sound that drones tend to make, but it's also the way that they look in flight: With uncannily linear movements and an even less canny ability to hover perfectly still, they tend to draw the eye as affronts to nature. In a paper presented this week at Robotics Science and Systems 2026 in Sydney, roboticists from Northwestern University, Evanston, Ill., demonstrated a drone called Phantom Twist that is essentially invisibl
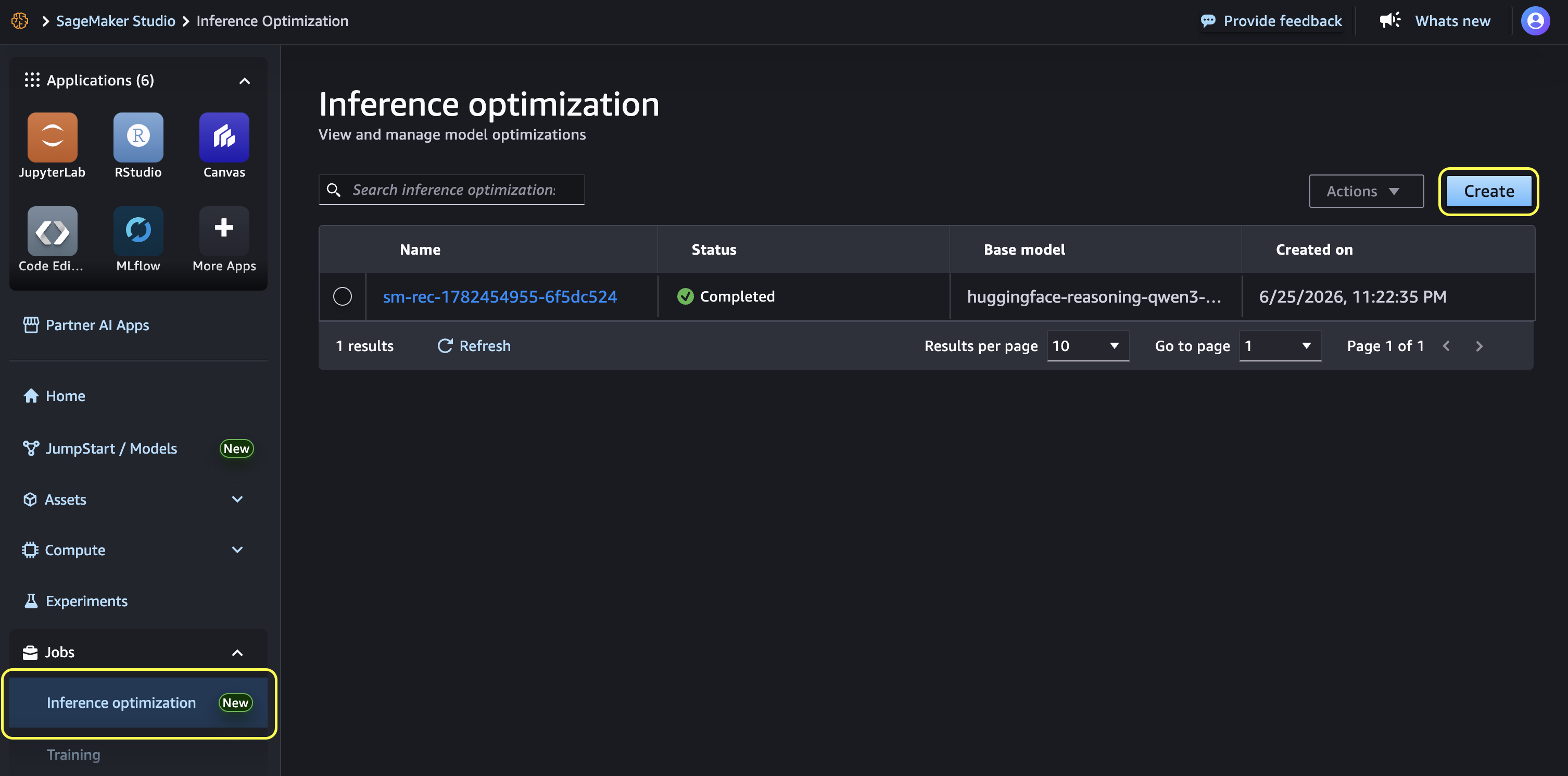
Launching UI for generative AI inference recommendations in Amazon SageMaker AI
In this post, we introduce the UI for optimized generative AI inference recommendations in Amazon SageMaker AI Studio, a low-code no-code (LCNC) experience. The API already gives you programmatic access to recommendations, but it assumes you know which parameters to set and how to interpret raw benchmark output. The UI removes that assumption. It guides you through preset use-case profiles, visual comparisons of results, and one-click deployment, so teams without deep infrastructure expertise can get a validated configuration on their own.

Fast token generation emerges as the key differentiator as heterogeneous inference takes hold
The race for fast token generation has moved from benchmark sheets into production data centers, and the hardware blueprint for winning it is no longer a GPU-only story. As agentic AI use cases multiply and users demand real-time interactivity, inference infrastructure is being redesigned from the rack up. The divide between compute-heavy prefill and latency-sensitive [...] The post Fast token generation emerges as the key differentiator as heterogeneous inference takes hold appeared first on SiliconANGLE.
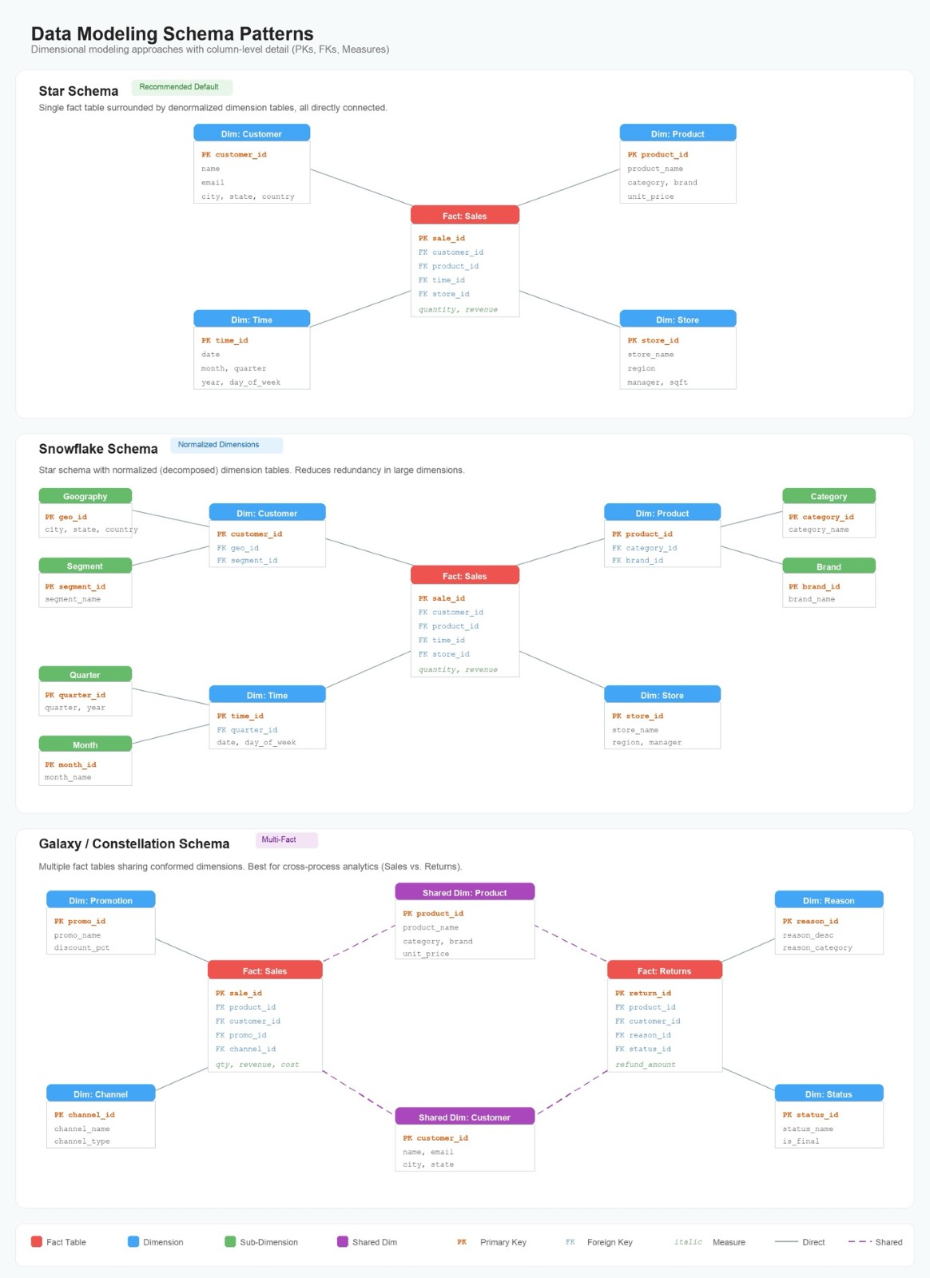
Data modeling best practices for Amazon Quick Sight multi-dataset relationships
Today, we are excited to announce Multi-Dataset Relationships in Amazon Quick Sight. This new capability lets you define logical relationships between Quick Sight datasets and perform runtime joins at query time. Instead of flattening tables ahead of time, you keep each table as its own Quick Sight dataset and declare how those datasets relate to one another inside a Quick Sight Topic.

Emily Bender Sets the Record Straight on "Stochastic Parrots"
In March 2021, a group of four researchers-a collaboration of linguists and computer scientists-published their now legendary paper "On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜" The paper received significant attention at the time (in part because Google fired two of the authors, Timnit Gebru and Margaret Mitchell, shortly before its publication). It argued that large language models (LLMs) generate text by statistically predicting likely sequences of words rather than understanding what they are saying-a process the authors captured with the metaphor of a "stochas

ConlangCrafter Turns AI to Imagining Languages
There are over 7,000 natural languages today, but that doesn't stop people from occasionally making up completely new ones. These constructed languages, or conlangs, include Dothraki, Klingon, and various Elvish languages. Now, an AI model called ConlangCrafter is also capable of generating new languages-and it is particularly good at it. In a paper published 27 June in the Proceedings of the Association of Computational Linguists, researchers analyzed ConlangCrafter's language-generation abilities, reporting that it can develop a diverse array of novel languages that consistently abide by the
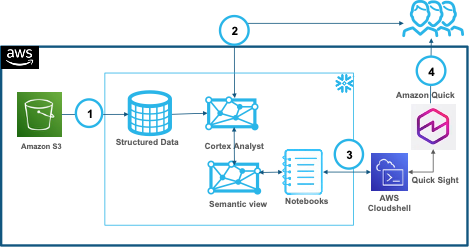
AI-powered BI with Snowflake and Amazon Quick
In this post, you will learn how to build an end-to-end integration between Snowflake semantic views and Amazon Quick. The sample data is user review data for a media company. You start by loading movie review data from Amazon Simple Storage Service (Amazon S3) into Snowflake, define a semantic view in SQL to add business meaning, explore it with natural-language queries through Cortex Analyst, and then generate an Amazon Quick dataset and dashboard. The dataset can be created manually or with a provided automation script. By the end, your BI team or AI team can ask natural-language questions

AI Is Designing Radio Chips That Humans Couldn't Even Imagine
Summary RFIC design is a complex "dark art" that limits progress in wireless technologies like 5G, autonomous vehicles, and satellite communications. Princeton researchers use reinforcement learning and inverse design to rapidly create RFICs from scratch. Diffusion models rapidly generate novel or human-interpretable RF layouts, achieving record performance and drastically reducing design time. Future progress needs large, shared chip design datasets and open ecosystems so AI can learn universal electromagnetic and circuit behaviors. Take a moment and try to imagine your life without the wirel

Hydrolix brings high-speed analytics to petabyte-scale agentic AI
The mission behind data management provider Hydrolix Inc. is fairly simple: to build the next generation of AI tools and provide AI-ready data for enterprises. Hydrolix's approach is designed to feed the growing agentic infrastructure. This is not simple, because agents demand millisecond response times and access to complete datasets for accuracy and timely decisions. Meeting [...] The post Hydrolix brings high-speed analytics to petabyte-scale agentic AI appeared first on SiliconANGLE.
NVIDIA Blackwell Leads on First Agentic AI Infrastructure Benchmark
NVIDIA reports that its Blackwell Ultra-based systems lead the first round of AgentPerf, an agentic AI infrastructure benchmark from Artificial Analysis. In the published results, the NVIDIA GB300 NVL72 platform ran up to 20x more agents per megawatt than older NVIDIA systems. The post explains why agentic AI is a fundamentally different workload than single chat completions and how AgentPerf measures real-world agentic performance using coding agent trajectories.

How to Open Files in CMD: A Quick Guide for 2026
You're probably here because of a very specific moment. An engineer shares a path to a config file, a dataset sample, or a log folder on Windows, and you realize you can't quickly inspect it without clicking through a maze of folders. Or you're on a call, someone says "just open it from cmd," and [...] The post How to Open Files in CMD: A Quick Guide for 2026 appeared first on Product Growth.

New Server Hopes to Break Through AI's "Memory Wall"
AI hardware startup Majestic Labs is building a new server called Prometheus with up to 128 terabytes of memory, over 60 times more than Nvidia's DGX B300, to address what the industry calls the memory wall in large language model inference. The company uses a DRAM-centric architecture with a proprietary copper-cable memory interface and custom aggregation chips. Prometheus pairs this memory with a custom AI processor called Ignite and supports common frameworks without code changes.

AI Rings on Fingers Can Interpret Sign Language
A new study describes a set of electronic rings, wirelessly connected to an AI system, that translate multiple sign languages into text. Led by Ki Jun Yu of Yonsei University, the work uses seven rings with accelerometers and a deep-learning system to recognize signs without smart gloves or cameras. In testing with people who did not help train the system, it recognized 100 American Sign Language and 100 International Sign Language words with 88.3 and 88.5 percent accuracy.

Identifying Interactions at Scale for LLMs
This Berkeley BAIR post introduces SPEX and ProxySPEX, algorithms designed to identify influential interactions in large machine learning systems, including large language models, at scale. It frames the work within interpretability research, which seeks to make model decision-making more transparent for safer and more trustworthy AI. The core challenge is that the number of possible interactions grows exponentially, making exhaustive analysis infeasible, so SPEX uses ideas from signal processing and coding theory to find the small set of interactions that truly drive behavior.
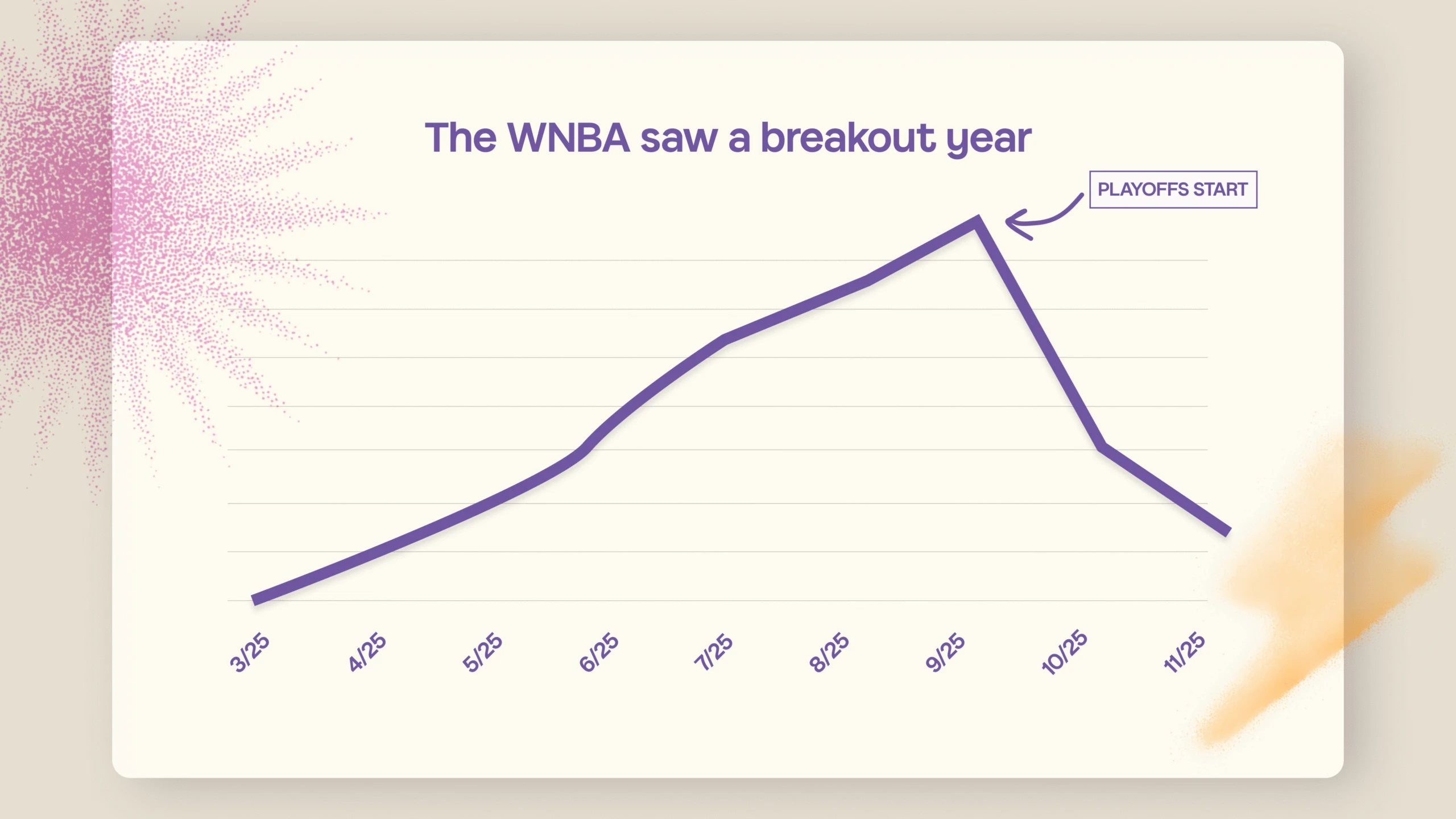
Main Character Energy: 2025 trend recap
Microsoft's Copilot team published a lighthearted 2025 trend recap from MAI, summarizing what people talked about with Copilot over the year. The post frames Copilot's mission as making the user the main character and shares playful comparisons of trending topics, with stats curated by MAI technical staff member Sophia Chen. It points readers to a fuller MAI blog post and paper for deeper analysis of how people use Copilot over time.

What exactly does word2vec learn?
Researchers from Berkeley's BAIR lab present a quantitative theory of how word2vec learns word representations. They prove that in realistic regimes the learning problem reduces to unweighted least-squares matrix factorization, and they solve the gradient flow dynamics in closed form so that the final representations are given by PCA. When trained from small initialization, word2vec learns one concept at a time in discrete steps, each incrementing the rank of the embedding matrix. The learned features turn out to be the top eigenvectors of a matrix defined by corpus statistics and hyperparameters.